Прошел месяц с появления моей
первой статьи на Хабре и 20 дней с момента появления
второй статьи про линейную регрессию. Статистика по просмотрам и целевым действиям аудитории копится, и именно она послужила отправной точкой для данной статьи. В ней мы коротко рассмотрим пример нелинейной регрессии (а именно, экспоненциальной) и с ее помощью построим модель конверсии, выделив среди пользователей две группы.
Когда известно, что случайная величина y зависит от чего-то (например, от времени или от другой случайной величины x) линейно, т.е. по закону y(x)= Ax+b, то применяется линейная регрессия (так
в прошлой статье мы строили зависимость числа регистраций от числа просмотров). Для линейной регрессии коэффициенты A и b вычисляются по известным формулам. В случае регрессии другого вида, например, экспоненциальной, для того чтобы определить неизвестные параметры, необходимо решить соответствующую оптимизационную задачу: а именно, в рамках метода наименьших квадратов (МНК) задачу нахождения минимума суммы квадратов (y(x
i) — y
i)
2.
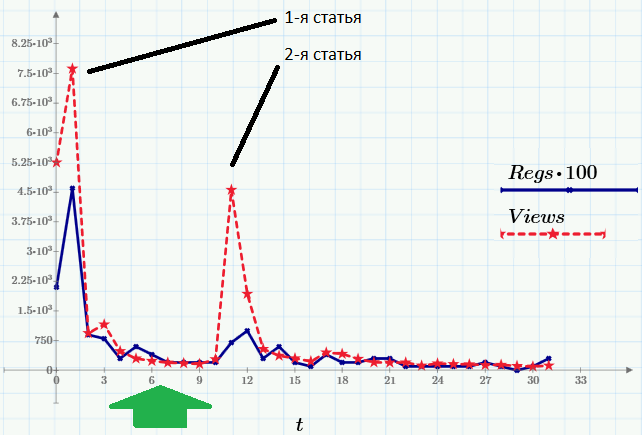
Итак, вот данные, которые будем использовать в качестве примера. Пики посещаемости (ряд Views, красный пунктир) приходятся на моменты выхода статей. Второй ряд данных (Regs, с множителем 100) показывает число читателей, выполнивших после прочтения определенное действие (регистрацию и скачивание Mathcad Express – с его помощью, к слову, вы сможете повторить все расчеты этой и предыдущих статей). Все картинки — это скриншоты Mathcad Express, а файл с расчетами вы можете взять
здесь.






 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как 




